mysql-字符集
Illegal mix of collations MySQL Error
// 查看哪个表的字符集有问题 |
编码注意
搜索中文
目前可用的是在连接数据库的时候指定编码 dbString = “ODBC;DSN=cxDMSmainMySQL;Trusted_Connection=Yes;CharSet=gbk;”;
使用 gbk 就可以正常了
当编码设为 utf8mb4 的时候,发现无法搜索到中文字段.
使用这个限定符 binary ucase. 之后,搜索的是全部数据,仍然不可用.
ucase 是忽略大小写.
sql = str::cstr::format("SELECT f_plate,f_plate_type,f_car_type,f_name,f_phone_1 FROM t_person_car_info,t_person_info WHERE \ |
查看字符集
show variables like '%char%'; |
连接登录设置字符集
mysql --default-character-set=字符集-u root -p |
设置字符集
这里的设置,只是当前有效,重启数据库后,会恢复默认的.
character_set_system:系统字符集,这个值总是utf8,不需要设置。这个字符集用于数据库对象(如表和列)的名字,也用于存储在目录表中的函数的名字。
collation_connection: 当前连接的字符集。
可以通过修改 my.ini 来设置默认字符集
[client] |
SET names utf8mb4 COLLATE utf8mb4_unicode_ci; |
SET names utf8 COLLATE utf8_unicode_ci; |
设置字节序 collation
字符序确定在同一字符集内字符之间的比较规则
查看当前字节序
show variables like '%colla%'; |
查看安装的字符序
show collation;
查看安装的字符集
show character set;
字节序的选择
结论就是使用 utf8mb4_unicode_ci.
字符除了需要存储,还需要排序或比较大小,涉及到与编码字符集对应的 排序字符集(collation)。ut8mb4对应的排序字符集常用的有 utf8mb4_unicode_ci, utf8mb4_general_ci
主要从排序准确性和性能两方面看:
准确性
utf8mb4_unicode_ci 是基于标准的Unicode来排序和比较,能够在各种语言之间精确排序
utf8mb4_general_ci 没有实现Unicode排序规则,在遇到某些特殊语言或字符是,排序结果可能不是所期望的。
但是在绝大多数情况下,这种特殊字符的顺序一定要那么精确吗。比如Unicode把ß、Œ当成ss和OE来看;而general会把它们当成s、e,再如ÀÁÅåāă各自都与 A 相等。性能
utf8mb4_general_ci 在比较和排序的时候更快
utf8mb4_unicode_ci 在特殊情况下,Unicode排序规则为了能够处理特殊字符的情况,实现了略微复杂的排序算法。
但是在绝大多数情况下,不会发生此类复杂比较。general理论上比Unicode可能快些,但相比现在的CPU来说,它远远不足以成为考虑性能的因素,索引涉及、SQL设计才是。 我个人推荐是 utf8mb4_unicode_ci,将来 8.0 里也极有可能使用变为默认的规则。相比选择哪一种collation,使用者应该更关心字符集与排序规则在db里要统一就好。
数据库配置文件
[client] |
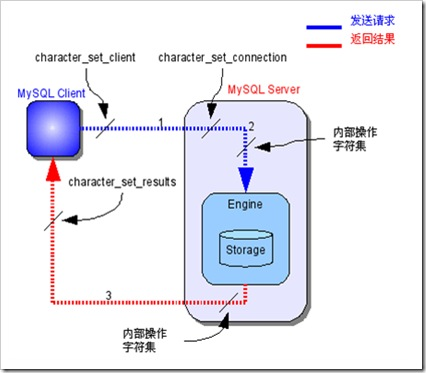
@@ MySQL数据库中字符集转换流程
MySQL收到请求时将请求数据从character_set_client转换为character_set_connection
进行内部操作前将请求数据从character_set_connection转换为内部操作字符集,其确定方法如下
使用每个数据字段的CHARACTER SET设定值
若上述值不存在,则使用对应数据表的DEFAULT CHARACTER SET设定值(MySQL扩展,非SQL标准)
若上述值不存在,则使用对应数据库的DEFAULT CHARACTER SET设定值
若上述值不存在,则使用character_set_server设定值
将操作结果从内部操作字符集转换为character_set_connection
将响应数据从character_set_connection转为character_set_client
执行SQL语句时信息的路径是这样的
信息输入路径:client → connection → server;
信息输出路径:server → connection → results.