sqlite-其他操作
判断表是否存在
//判断表是否存在 |
创建数据库
获取记录总数
获取记录总数 |
f_id_noise integer 0
select * from t_3764846313_5539326756021866496 where f_id_noise=1476754630 ORDER BY f_datetime DESC LIMIT 1
//判断表是否存在 |
获取记录总数 |
f_id_noise integer 0
select * from t_3764846313_5539326756021866496 where f_id_noise=1476754630 ORDER BY f_datetime DESC LIMIT 1
sql = "INSERT INTO t_outlet (id,parentId) VALUES (null,?),"; |
先删除,后插入,key 会有增长
The idea of the REPLACE statement is that when a UNIQUE or PRIMARY KEY constraint violation occurs, it does the following:
First, delete the existing row that causes a constraint violation.
Second, insert a new row.
In the second step, if any constraint violation e.g., NOT NULL constraint occurs, the REPLACE statement will abort the action and roll back the transaction.
REPLACE INTO table(column_list) |
wstring sql = L"INSERT INTO t_geometric_coeff (f_id,f_name,f_notes,f_value) VALUES (?,?,?,?) ON CONFLICT (f_id) DO UPDATE SET f_name=excluded.f_name,f_notes=excluded.f_notes,f_value=excluded.f_value where f_id=excluded.f_id;"; |
string sql = "select count(*) from t_user where f_name=? and f_pwd=?"; |
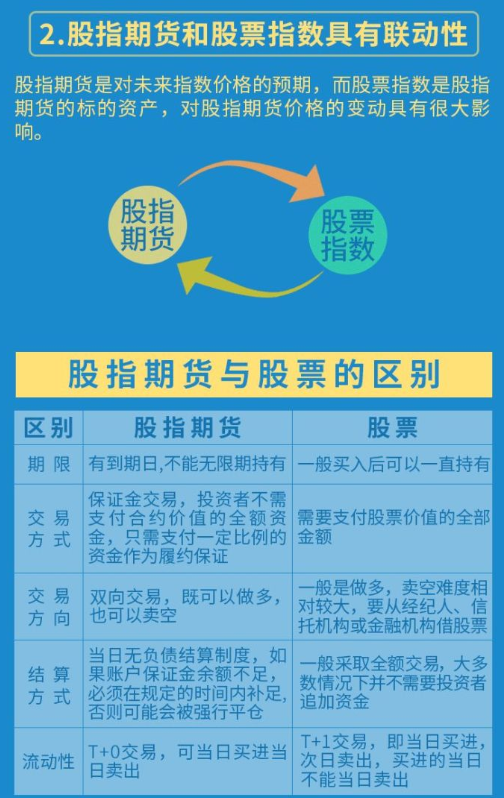
借钱买股和借股卖股的过程也叫开仓。
在这个过程中,有两个角色,分别是客户和券商,券商借给你钱,借给你券,你呢,为此支付利息,年化8%~14%之间。
你借的钱,和股票,就叫做负债
借了钱,借了股票当然要还,这个期限最长不能超过180天,当然,在这期限之内,你可以随借随还
你还钱的过程,叫做还款,可以直接现金还,也可以用卖了股票得来的资金还。
你还股票的过程,叫做还券,可以直接用持仓的股票还,也可以买入股票还。
当然,还款和还券的同时,要把对应的利息和手续费一起还上。
还钱还股票的过程,也叫平仓。
买涨过程,就和我们现在的买股票是一模一样的,先买后卖。收益就是价差。
卖空,就是先把从券商借来的股票按照当前价卖掉,然后在找个低价买回来。
买涨股票好理解,买入的时候有了买入成本价,持有的时候,现价就是你的卖出价,你的收益就是【(卖出价(现价)-买入成本价】数量。
卖空操作呢,是先有了卖出价,你的买入成本价成了随时变动的现价,啥时候你买入了,这个时候你的收益就是【卖出价-现价(买入价)】数量
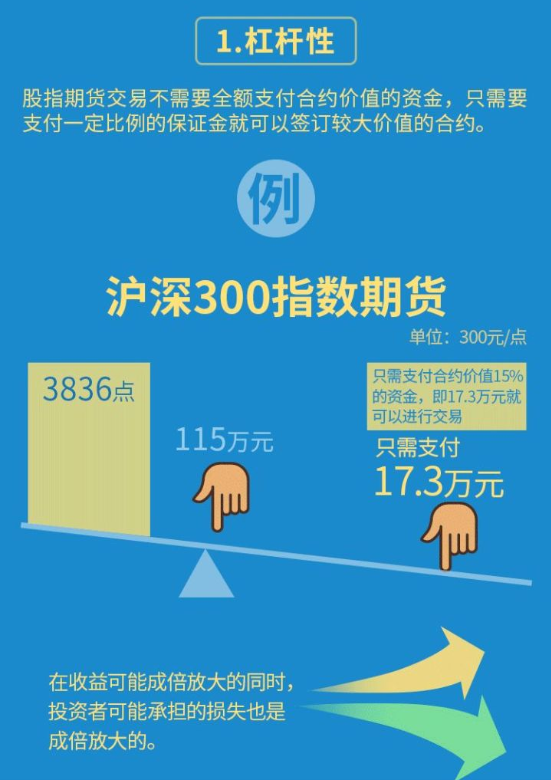
股指期货品种:
沪深300指数期货(代码IF)2010年4月16日
上证50指数期货(代码IH)2015年4月16日
中证500指数期货(代码IC)2015年4月16日
特点:
杠杆性
随机数生成算法有很多,C++11之前的C/C++只用了一种。C++11则提供下面三种可供选择:
C++11中的原子操作
原子操作, 它表示在多个线程访问同一个全局资源的时候, 能够确保所有其他的线程都不在同一时间内访问相同的资源. 也就是他确保了在同一时刻只有唯一的线程对这个资源进行访问. 这有点类似互斥对象对共享资源的访问的保护, 但是原子操作更加接近底层, 因而效率更高.
SnowFlake算法生成id的结果是一个64bit大小的整数,它的结构如下图:
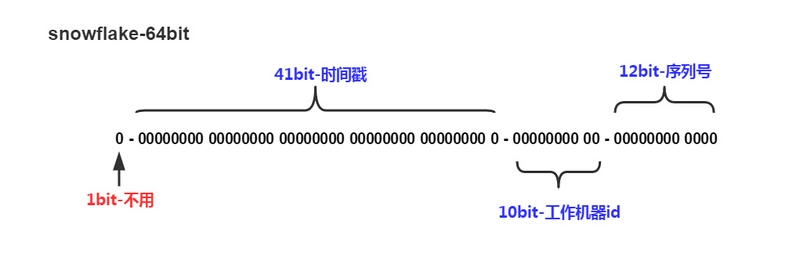
41位可以表示$2^{41}-1$个数字,
如果只用来表示正整数(计算机中正数包含0),可以表示的数值范围是:0 至 $2^{41}-1$,减1是因为可表示的数值范围是从0开始算的,而不是1。
也就是说41位可以表示$2^{41}-1$个毫秒的值,转化成单位年则是$(2^{41}-1) / (1000 * 60 * 60 * 24 * 365) = 69$年
注意, 这里存储的不是当前的时间戳,而是存储时间戳的差值(当前时间截 - 开始时间截), 可以表示69年的时间.
可以部署在$2^{10} = 1024$个节点,包括5位datacenterId和5位workerId
5位(bit)可以表示的最大正整数是$2^{5}-1 = 31$,即可以用0、1、2、3、….31这32个数字,来表示不同的datecenterId或workerId
12位(bit)可以表示的最大正整数是$2^{12}-1 = 4095$,即可以用0、1、2、3、….4094这4095个数字,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号
SnowFlake可以保证:
所有生成的id按时间趋势递增
整个分布式系统内不会产生重复id(因为有datacenterId和workerId来做区分)
std::move 并不会真正地移动对象,真正的移动操作是在移动构造函数、移动赋值函数等完成的,std::move 只是将参数转换为右值引用而已(相当于一个 static_cast)
std::move函数可以以非常简单的方式将左值引用转换为右值引用。
通过std::move,可以避免不必要的拷贝操作。
std::move是为性能而生。
std::move是将对象的状态或者所有权从一个对象转移到另一个对象,只是转移,没有内存的搬迁或者内存拷贝。
document.ready和onload的区别——JavaScript文档加载完成事件
页面加载完成有两种事件:
一是ready,表示文档结构已经加载完成(不包含图片等非文字媒体文件)
二是onload,指示页面包含图片等文件在内的所有元素都加载完成。
<script type=”text/javascript”> |