kotlin-datetime
下面是 java 代码,
Timestamp timestamp = new Timestamp(System.currentTimeMillis()); |
获取时间
val current = LocalDateTime.now() |
timestamp to date
val stamp = Timestamp(System.currentTimeMillis()) |
下面是 java 代码,
Timestamp timestamp = new Timestamp(System.currentTimeMillis()); |
val current = LocalDateTime.now() |
val stamp = Timestamp(System.currentTimeMillis()) |
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选。
它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它。
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
不过,Elasticsearch不仅仅是Lucene和全文搜索,我们还能这样去描述它:
分布式的实时文件存储,每个字段都被索引并可被搜索
分布式的实时分析搜索引擎
可以扩展到上百台服务器,处理PB级结构化或非结构化数据
分布式的搜索引擎和数据分析引擎
全文检索,结构化检索,数据分析
作为传统数据库的一个补充,提供了数据库所不能提供的很多功能
ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储以及全文检索
logstash: 日志加工、“搬运工”
kibana:数据可视化展示。
ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作。
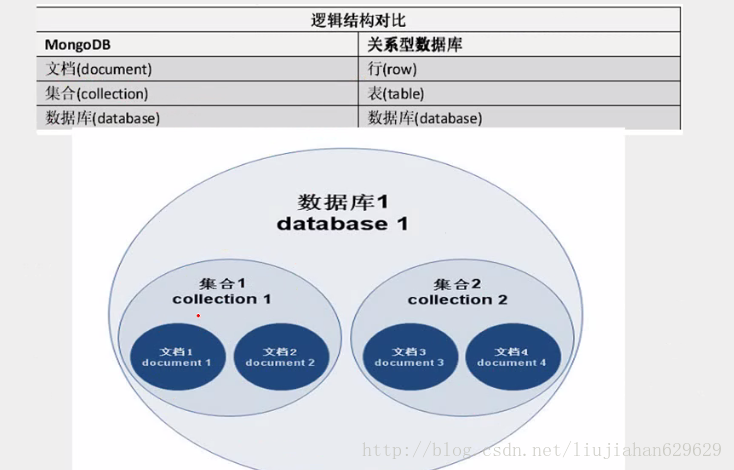
MongoDB是一种面向文档的数据库管理系统,由C++撰写而成,
MongoDB(来自于英文单词“Humongous”,中文含义为“庞大”)是可以应用于各种规模的企业、各个行业以及各类应用程序的开源数据库。作为一个适用于敏捷开发的数据库,MongoDB的数据模式可以随着应用程序的发展而灵活地更新。
MongoDB是专为可扩展性,高性能和高可用性而设计的数据库。它可以从单服务器部署扩展到大型、复杂的多数据中心架构。利用内存计算的优势,MongoDB能够提供高性能的数据读写操作。 MongoDB的本地复制和自动故障转移功能使您的应用程序具有企业级的可靠性和操作灵活性。
日志系统是每个程序必然需要的基础设施,在学习 spring boot 的过程中,涉及到了 logback 库的使用,这里记录一下。
目前只是本地存储,后面应该需要搭建一个日志服务做集中管理。
SLF4J (Simple Logging Facade For Java),它是一个针对于各类Java日志框架的统一Facade抽象。
SLF4J定义了统一的日志抽象接口,而真正的日志实现则是在运行时决定。
日志级别有 TRACE < DEBUG < INFO < WARN < ERROR < OFF (output no logs)
Logback 配置文件 logback-spring.xml
Logback 是 log4j 框架的作者开发的新一代日志框架,它效率更高、能够适应诸多的运行环境,同时原生支持 SLF4J。
官网手册
记录一下常用操作,方便查找
注意区分可变和不可变的声明和使用
| 只读 | 可读写 |
|---|---|
| Collection |
MutableCollection |
| List |
MutableList |
| Set |
MutableSet |
| Map<K, out V> | MutableMap<K, V> |
这本书已经看了3遍了,似乎还有看不到的东西在里面,不知道为什么,有点喜欢读这本书了,作者不是职业作家,所以没有清晰的脉络,而是很随性的叙述,有种在宝藏里面寻宝的感觉,似乎这样理解的更深刻一些,反而比一条条列出来的效果更好些。
“书读百遍其义自见” 不用真的读100遍吧。

所有的异常类都继承至 Throwable,每个异常包括 message, stack trace 和可选的 cause
依赖于4个关键字 try, catch, finally, throw。
throw MyException("Hi There!") |
catch 块可以0-n个,finally 块可以省略,但是至少有一个 catch 或者 finally 块。
try { |
try 语句是表达式
fun getUser(uid: Long): User? { |