序列化库FlatBuffers
FlatBuffers 是一个开源的、跨平台的、高效的、提供了 C++/Java 接口的序列化工具库。它是 Google 专门为游戏开发或其他性能敏感的应用程序需求而创建。尤其更适用于移动平台,这些平台上内存大小及带宽相比桌面系统都是受限的,而应用程序比如游戏又有更高的性能要求。它将序列化数据存储在缓存中,这些数据既可以存储在文件中,又可以通过网络原样传输,而不需要任何解析开销。
为什么要使用 Google FlatBuffers
- 对序列化数据的访问不需要打包和拆包——它将序列化数据存储在缓存中,这些数据既可以存储在文件中,又可以通过网络原样传输,而没有任何解析开销;
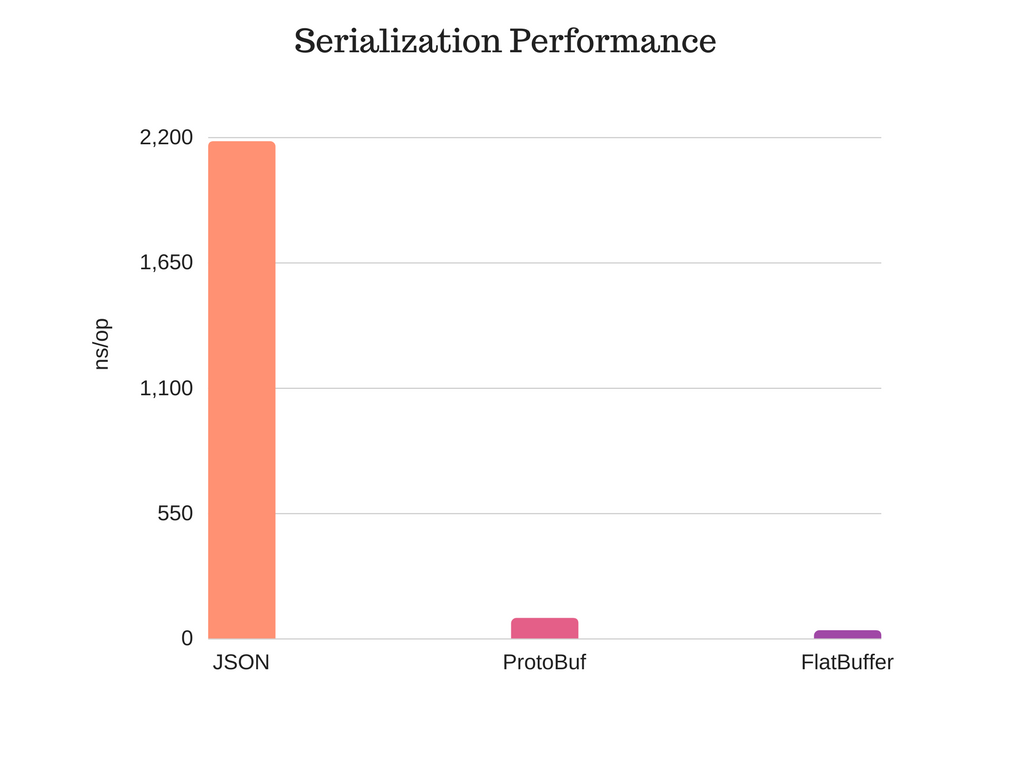
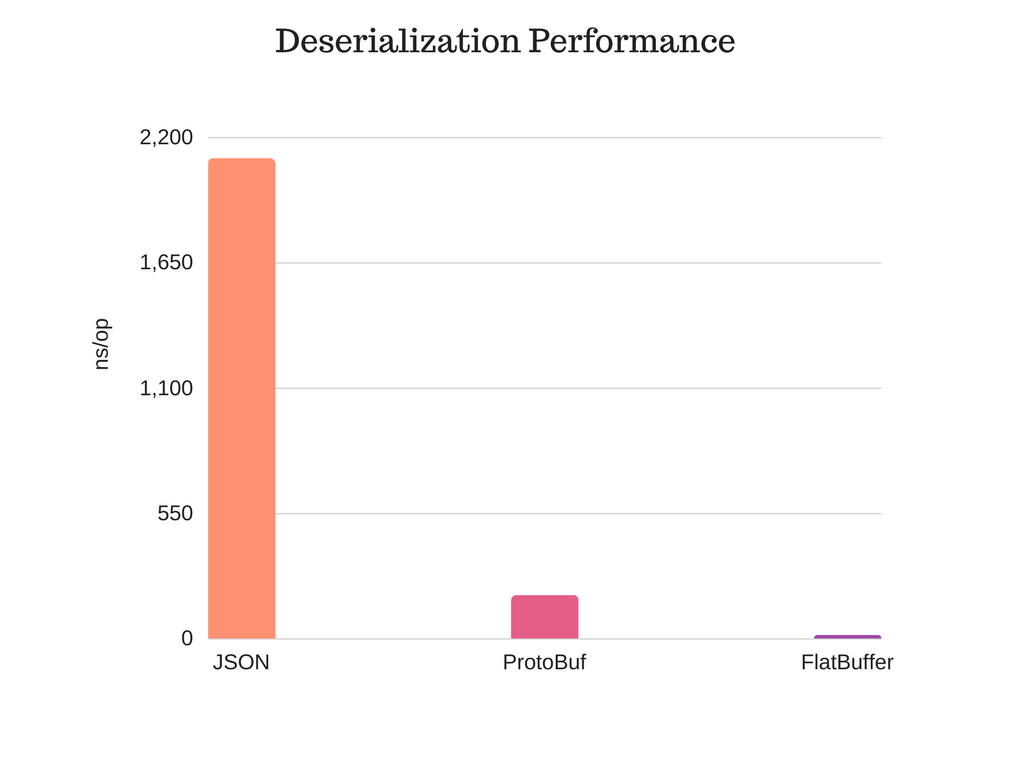
- 内存效率和速度——访问数据时的唯一内存需求就是缓冲区,不需要额外的内存分配。 这里可查看详细的基准测试;
- 扩展性、灵活性——它支持的可选字段意味着不仅能获得很好的前向/后向兼容性(对于长生命周期的游戏来说尤其重要,因为不需要每个新版本都更新所有数据);
- 最小代码依赖——仅仅需要自动生成的少量代码和一个单一的头文件依赖,很容易集成到现有系统中。再次,看基准部分细节;
- 强类型设计——尽可能使错误出现在编译期,而不是等到运行期才手动检查和修正;
- 使用简单——生成的 C++代码提供了简单的访问和构造接口;而且如果需要,通过一个可选功能可以用来在运行时高效解析 Schema 和类 JSON 格式的文本;
- 跨平台——支持 C++11、Java,而不需要任何依赖库;在最新的 gcc、clang、vs2010 等编译器上工作良好;
和 protocol buffer,json 区别
Protocol Buffers 的确和 FlatBuffers 比较类似,但其主要区别在于 FlatBuffers 在访问数据前不需要解析/拆包这一步。 而且 Protocol Buffers 既没有可选的文本导入/导出功能,也没有 Schemas 语法特性(比如 union)。
JSON 是非常可读的,而且当和动态类型语言(如 JavaScript)一起使用时非常方便。然而在静态类型语言中序列化数据时,JSON 不但具有运行效率低的明显缺点,而且会让你写更多的代码来访问数据(这个与直觉相反)。