python-hdf5
还是不使用这个了,在保存 dataframe 的时候有问题,比较麻烦。
store = pd.HDFStore('demo.h5') |
h5py 保存 dataframe 好像问题很多,没有继续尝试了,直接使用了 HDFStore
conda install h5py |
一般的操作一个HDF5对象的步骤是
- 打开这个对象;
- 对这个对象进行操作;
- 关闭这个对象。
特别要注意的是,一定要在操作结束后关闭对象。因为之前的操作只是生成操作的流程,并不真正执行操作,只有关闭对象操作才会真正出发对对象进行的修改。import h5py
# 以写入方式打开文件
# r 只读,文件必须已存在
# r+ 读写,文件必须已存在
# w 新建文件,若存在覆盖
# w- 或x,新建文件,若存在报错
# a 如存在则读写,不存在则创建(默认)
file = h5py.File('file.h5', 'a')
file.close()
# 打开文件
file_open = h5py.File('file.h5', 'r+')
file_open.close()
def h5_demo():
# 读文件放入内存
with h5py.File('demo.h5', mode='a',driver='core',backing_store=True) as file:
file.close()
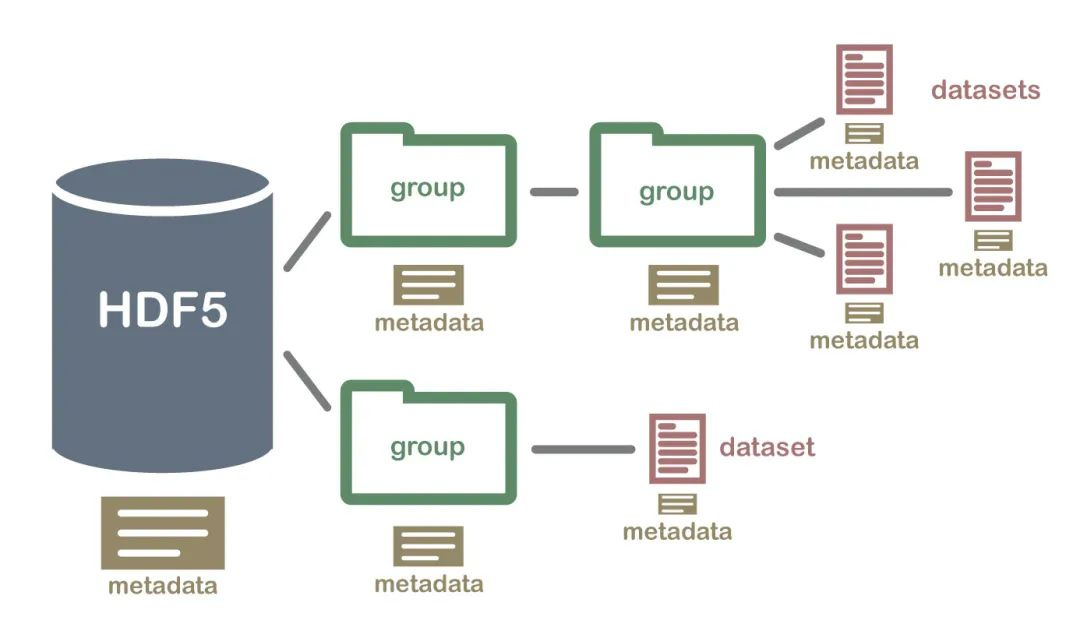
Groups
Datasets
Groups
group 是主要的组织结构,类似于 dictionary ,key 是 group 的名字,value 是属于该组的内容,可以是 group 和 datasets
keys() |
Datasets
# 创建新的 |
hdfstore
store = pd.HDFStore('demo.h5') |