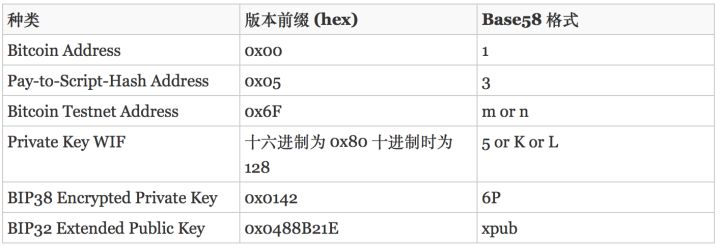
我们怎么样理解钱包呢?简单讲它是连接区块链的一个入口。目前比较成熟的公链,如比特币、以太坊都有很多钱包可以选择。一般钱包需要完全访问你的用户资产,也就是会要求你输入私钥。钱包的作恶成本极低,这也是笔者建议选择开源钱包的原因之一。
加密数字货币钱包提供钱包地址的创建、加密数字货币转账、每个钱包地址交易历史的查询等基础金融功能。
通信协议 RPC、JSON-RPC 以及 JSON
JSON-RPC,是一个无状态且轻量级的远程过程调用(RPC)传送协议,其传递内容通过 JSON 为主。相较于一般的 REST 通过网址(如 GET /user)调用远程服务器,JSON-RPC 直接在内容中定义了欲调用的函数名称(如 {“method”: “getUser”}),这也令开发者不会陷于该使用 PUT 或者 PATCH 的问题之中。 本规范主要定义了一些数据结构及其相关的处理规则。它允许运行在基于 Socket、HTTP 等诸多不同消息传输环境的同一进程中。其使用 JSON(RFC 4627)作为数据格式。[2]
我们以比特币为例,根据 Original Bitcoin client/API calls list 文档我们可以得到 RPC 接口提供的函数列表。
以 sendrawtransaction 为例,这个函数列表提供了四列(Command、Parameters、Description、Requires unlocked wallet? ),分别表示函数名、传入参数、描述、是否需要解锁钱包。
我们把这个函数列表掌握之后,可以选择某一种语言,然后进行区块链钱包相关的开发。
安全 通常意义上的数字资产安全其实就是私钥的安全,
360的安全白皮书
Wallet 钱包里只含有钥匙,比特币钱包是密钥链。
比特币的所有权是通过数字密钥、比特币地址和数字签名来确立的。数字密钥实际上并不是存储在网络中,而是由用户生成并存储在一个文件或简单的数据库中,称为钱包。存储在用户钱包中的数字密钥完全独立于比特币协议,可由用户的钱包软件生成并管理,而无需区块链或网络连接。
有两种主要类型的钱包,区别在于它们包含的多个密钥是否相互关联。
第一种类型是非确定性钱包(nondeterministic wallet),其中每个密钥都是从随机数独立生成的。密钥彼此无关。这种钱包也被称为“Just a Bunch Of Keys(一堆密钥)”,简称JBOK钱包。
第二种类型是确定性钱包(deterministic wallet),其中所有的密钥都是从一个主密钥派生出来,这个主密钥即为种子(seed)。该类型钱包中所有密钥都相互关联,如果有原始种子,则可以再次生成全部密钥。确定性钱包中使用了许多不同的密钥推导方法。最常用的推导方法是使用树状结构,称为分级确定性钱包或HD钱包。
根据区块链数据的维护方式,我们可以把钱包分为
全节点(如 bitcoin-core 核心钱包),维护着全部的区块链数据(当前在50GB以上),完全去中心化,同步所有数据;
SPV轻钱包(如比太),只维护与自己相关的区块链数据,基本上去中心化(要依赖比特币网络上的其他全节点),仅同步与自己相关的数据;
中心化钱包,不依赖比特币网络,只依赖自己的中心化服务器,不同步数据,所有的数据均从自己的中心化服务器中获得;
根据所使用的硬件设备,我们可以把钱包分为:
电脑钱包,钱包软件运行于桌面操作系统(Windows、MacOS、Linux等);
手机钱包,安卓、iOS等;
在线钱包(如 blockchain.info ),运行与云服务,私钥加密存储于服务器上,通过浏览器访问;
硬件钱包,运行与专门定制的硬件上,可能需要与电脑或手机配合使用;
比太钱包
钱包最佳实践 助记码,基于BIP-39BIP39 标准定义了钱包助记词和种子生成规则
多重签名 普通钱包:A想转给X一个比特币,A只需要自己的签名(使用私钥)就可以完成交易
多重签名钱包:A想转给X一个比特币,设置了一个多重签名(ABC3个人需要2个签名才能转账),那么A想给X转账的时候需要B或C也完成签名(使用私钥)。
如果设置了多重签名,那么任何一个私钥泄露都不会损失你的数字资产。
UTXO 代表 Unspent Transaction Output, 表示未花费的输出。 特点:
每个UTXO都是独一无二的,就好像带有编码的钞票一样
相比钞票来说,UTXO更灵活,并没有固定面额的限制,任意数额都可以
UTXO是不能分割的,只能被消耗掉
在交易前后,UTXO的数量可能增多,也可能减少
每笔交易的输入和输出都是有关系的,可以通过UTXO不停往前追溯,直到挖矿
优势
UTXO具备天然的匿名性
UTXO是独立的数据结构,可以更好的并行处理。
长期来看,UTXO的数据占用更小,而余额系统会越来越臃肿。
UTXO的结构更不容易被篡改,每个UTXO都追根溯源,很难伪造。
HD钱包(Hierarchical Deterministic)
HD钱包根据“种子”(种子密钥)按顺序导出未来的地址,每个新地址相当于“种子+计数器”。通过这种方式,你只用一个种子就可以恢复所有的私钥和地址。
目前很多钱包都是HD钱包,只需要备份助记词即可,简化了创建新私钥和备份私钥的方式。
大家都知道,一个私钥对应一个地址,每个地址类似你的银行卡,私钥类似你的银行卡密码。
比特币也是同样的道理,如果比特币数量较大,不建议大家把所有比特币放在一个地址里。这个时候你就有几个痛点:
每次生成一个新地址都需要备份一遍私钥,操作麻烦
生成了一堆私钥,管理起来很不方便
HD钱包可以快速方便的生成多个地址,并且不需要备份对应的私钥。你只需要一个种子密钥就可以把所有的私钥和地址全部恢复。
但是也有一个巨大的风险——种子丢了相当于丢了一堆钱包的私钥
HD钱包的优缺点 参考
您只需要备份一个种子(种子密钥),不需要备份私钥
可以快速生成很多地址
有效保护财务隐私
种子丢失或被盗,种子下生成的所有地址都丢失或被盗
BIP32 (Bitcoin Improvement Proposal 32)
符合 BIP-32/BIP-44 标准的 HD 钱包
BIP39 标准就是为了解决助记词的需求,通过随机生成 12 ~ 24 个容易记住的单词,单词序列通过 PBKDF2 与 HMAC-SHA512 函数创建出随机种子作为 BIP32 的种子
BIP39-go testify
BIP39 标准定义了钱包助记词和种子生成规则。
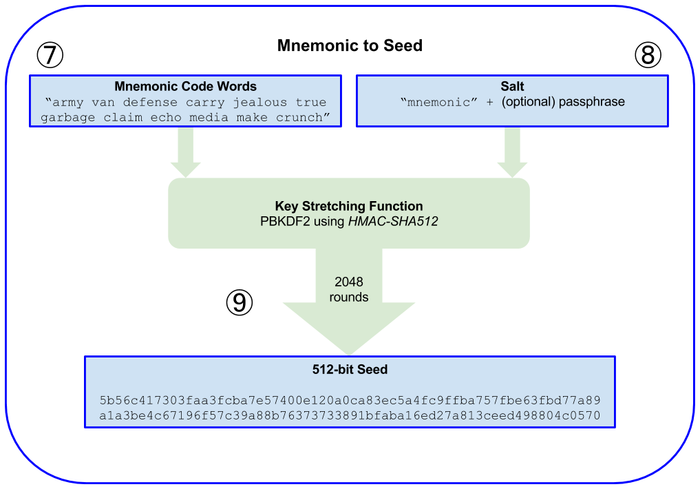
通过九个步骤即可生成钱包助记词和种子:6 生成助记词9 把前六步生成的助记词转化为 BIP32 种子
生成助记词
规定熵的位数必须是 32 的整数倍,所以熵的长度取值位 128 到 256 之间取 32 的整数倍的值,分别为 128, 160, 192, 224, 256;
校验和的长度为熵的长度/32 位, 所以校验和长度可为 4,5,6,7,8 位;
助记词库有 2048 个词,用 11 位可全部定位词库中所有的词,作为词的索引,故一个词用 11 位表示,助记词的个数可为 (熵+校验和)/11,值为 12,15,18,21,24
熵(bits)
校验和(bits)
熵 + 校验和 (bits)
助记词长度
128
4
132
12
160
5
165
15
192
6
198
18
224
7
231
21
256
8
264
24
生成一个长度为 128~256 位 (bits) 的随机序列(熵)
取熵哈希后的前 n 位作为校验和 (n= 熵长度/32)
随机序列 + 校验和
把步骤三得到的结果每 11 位切割
步骤四得到的每 11 位字节匹配词库的一个词
步骤五得到的结果就是助记词串
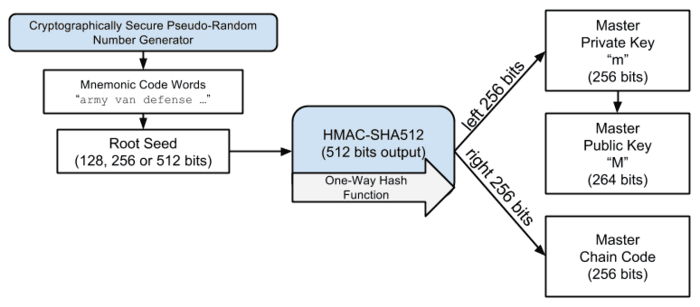
通过助记词生成种子
为了从助记词中生成二进制种子,BIP39 采用 PBKDF2 函数推算种子,其参数如下:
助记词句子作为密码
“mnemonic” + passphrase 作为盐
2048 作为重复计算的次数
HMAC-SHA512 作为随机算法
512 位(64 字节)是期望得到的密钥长度
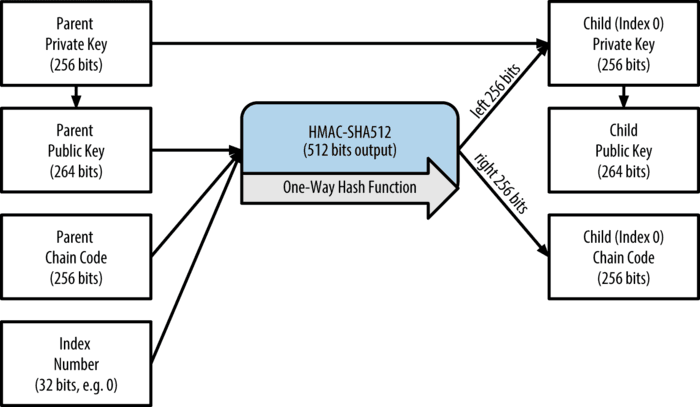
BIP32 标准定义了 HD 钱包的生成规则。HD 钱包中的所有层级密钥都是由根种子推导而来,通常根种子由上述步骤 BIP39 生成。所以只需通过助记词就能备份和恢复钱包,这也是 HD 钱包的缺陷,如果你的根种子泄漏,那么全部密钥随之都泄漏。
主私钥和主链码
父密钥 (没有压缩过的椭圆曲线推导的私钥或公钥 ECDSA uncompressed key)
链码作为熵 (chain code 256 bits)
子代索引序号 (index 32 bits)
索引号个数为 2 的 32 次方,每个父级密钥能推导出该数目一半的子密钥 (
钱包地址生成 参考
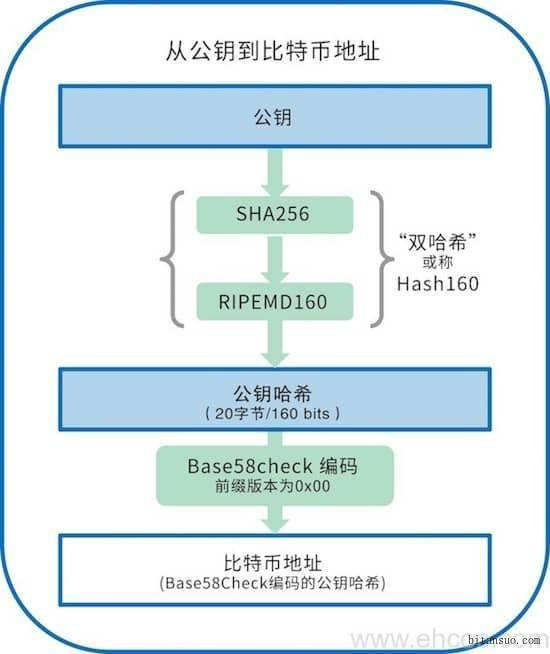
比特币地址由一个公钥生成并对应于这个公钥。地址与公钥之间的关系,如下图所示:
这里用(RIPEMD16(SHA256(PubKey))算法
获取公钥,用 RIPEMD160(SHA256(PubKey)) 的哈希算法哈希两次。
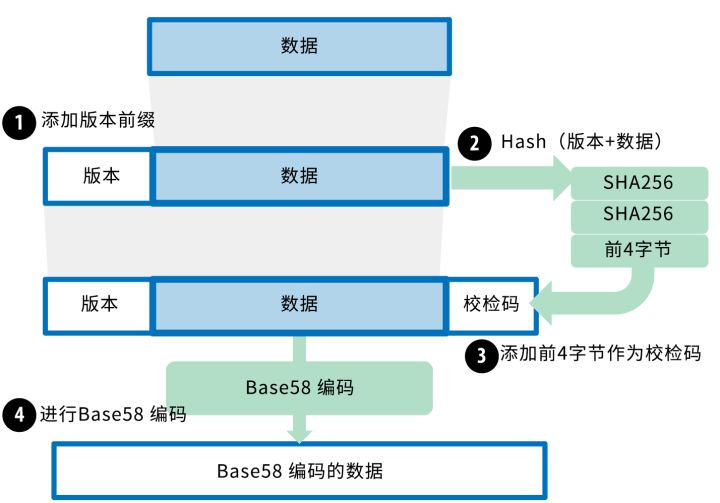
准备转哈希地址生成算法的版本
通过用 SHA256(SHA256(payload)) 哈希步骤 2 的结果计算 checksum。这个 checksum 是哈希结果的头四个字节。
准备 checksum 到 version+PubKeyHash 的组合。
用 Base58 编码 version+PubKeyHash+checksum 的组合。
base58校验 https://blockchain.info/address/1A1zP1eP5QGefi2DMPTfTL5SLmv7DivfNa
00d296d3a4f2307fe17e2e51398f03a8dcc998e1d67f38858d Mnemonic: toilet bottom much member impact film tornado used dinner shove aware bamboo work sustain ticket yellow stem guess story friend virtual elevator fiber pig Master private key: xprv9s21ZrQH143K3wBFoUh64FXLnZwGr9S5v1GprnkBHzms5xNZDHnbcucE5Y9BUo1FoE45pMCzxbr3xmduC8HWpmMQEg3FLUbzV7XuxUGxqXj Master public key: xpub661MyMwAqRbcGRFiuWE6RPU5LbmmFc9wHECRfB9nrLJqxkhhkq6rAhvhvpcv1pWdNtF8H61am1vvi5iq8NLejVo6pcvAqGeACDe7XSoZjLa wallet address: 1LCVaumEKaxAC2htJDnbDPNotexEpLoi6g
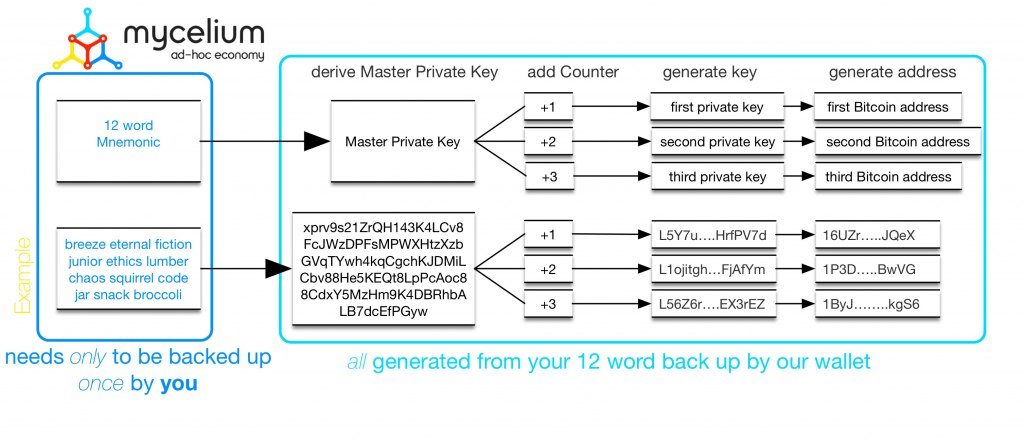 HD钱包根据“种子”(种子密钥)按顺序导出未来的地址,每个新地址相当于“种子+计数器”。通过这种方式,你只用一个种子就可以恢复所有的私钥和地址。
HD钱包根据“种子”(种子密钥)按顺序导出未来的地址,每个新地址相当于“种子+计数器”。通过这种方式,你只用一个种子就可以恢复所有的私钥和地址。
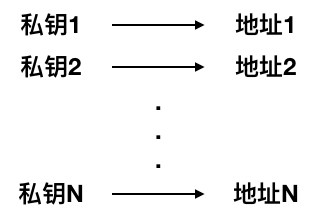
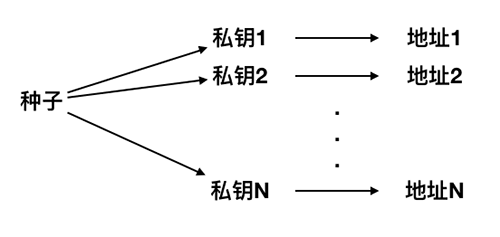 HD钱包可以快速方便的生成多个地址,并且不需要备份对应的私钥。你只需要一个种子密钥就可以把所有的私钥和地址全部恢复。
但是也有一个巨大的风险——种子丢了相当于丢了一堆钱包的私钥
HD钱包可以快速方便的生成多个地址,并且不需要备份对应的私钥。你只需要一个种子密钥就可以把所有的私钥和地址全部恢复。
但是也有一个巨大的风险——种子丢了相当于丢了一堆钱包的私钥
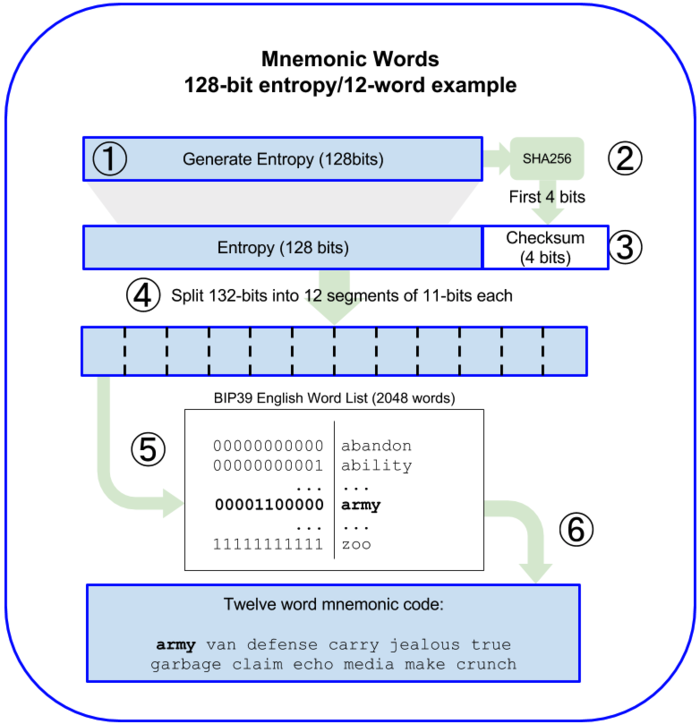
 BIP32 标准定义了 HD 钱包的生成规则。HD 钱包中的所有层级密钥都是由根种子推导而来,通常根种子由上述步骤 BIP39 生成。所以只需通过助记词就能备份和恢复钱包,这也是 HD 钱包的缺陷,如果你的根种子泄漏,那么全部密钥随之都泄漏。
BIP32 标准定义了 HD 钱包的生成规则。HD 钱包中的所有层级密钥都是由根种子推导而来,通常根种子由上述步骤 BIP39 生成。所以只需通过助记词就能备份和恢复钱包,这也是 HD 钱包的缺陷,如果你的根种子泄漏,那么全部密钥随之都泄漏。